Meta's Autodata: Autonomous AI Agents That Revolutionize Training Data Creation
Introduction
For years, the AI community has fixated on scaling compute to improve model performance. But Meta AI’s RAM team argues that the real bottleneck lies elsewhere: data quality. Their new framework, Autodata, tackles this head-on by transforming large language models into autonomous data scientists that iteratively generate, evaluate, and refine training datasets—without constant human oversight. Early tests on complex scientific reasoning tasks reveal that Autodata doesn’t just match existing synthetic data methods; it significantly surpasses them.
Why Synthetic Data Creation Is Challenging
To grasp Autodata’s significance, it helps to understand current synthetic data pipelines. Initially, AI systems relied on human-written examples. As models advanced, researchers turned to synthetic data—content generated by the model itself. This approach can produce rare edge cases, cut labeling costs, and deliver harder examples than those found in public datasets.
The dominant method has been Self-Instruct, where a large language model (LLM) is prompted with zero-shot or few-shot examples to create new training samples. Enhanced versions—like Grounded Self-Instruct—anchor generation on external documents to reduce hallucinations and boost diversity. Chain-of-Thought Self-Instruct goes further by using reasoning chains during generation to build more complex tasks. Most recently, Self-Challenging methods let a challenger agent interact with tools before proposing a task and evaluation function—the closest predecessor to Autodata.
Yet none of these approaches offer a feedback-driven loop to control or iteratively improve data quality during generation. Filtering, evolving, or refining could happen post-generation, but the pipeline itself remained static and single-pass. Autodata breaks this barrier.
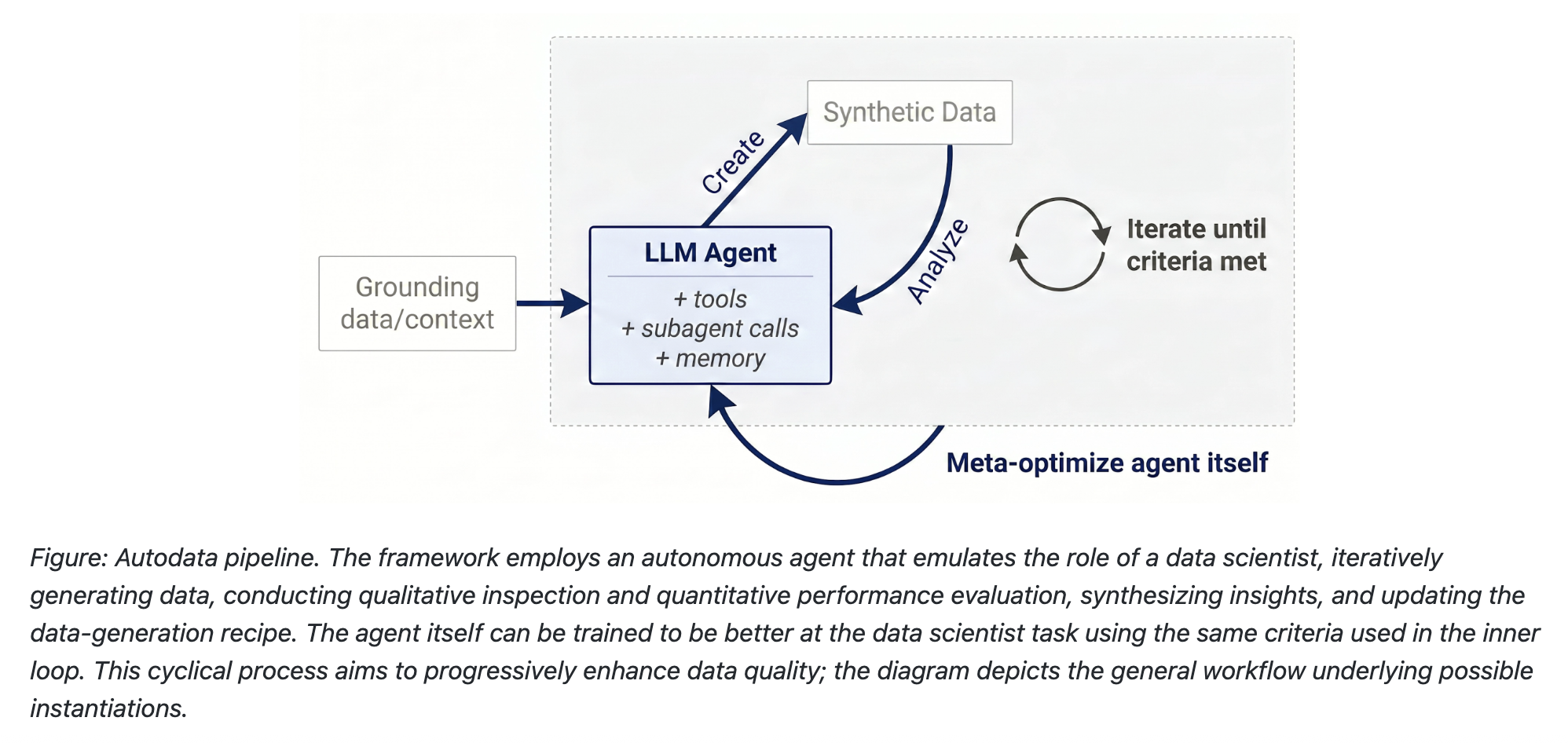
How Autodata Works
Autodata deploys AI agents as autonomous data scientists that run a closed-loop pipeline inspired by human workflow. Here’s the three-step process:
1. Data Creation
The agent grounds itself on provided source documents—research papers, code snippets, legal texts, etc.—and uses tools and learned skills to generate training or evaluation examples. This ensures relevance and accuracy.
2. Data Analysis
After generation, the agent inspects each example for correctness, quality, and challenge level. It can identify issues like factual errors, low diversity, or insufficient difficulty.
3. Iterative Refinement
Based on analysis, the agent revisits and improves the data—adjusting prompts, adding constraints, or generating new variants. This loop continues until quality targets are met, making Autodata a truly dynamic generator.
Impact and Results
Initial tests on scientific reasoning benchmarks show that Autodata outperforms classical synthetic data methods by a notable margin. The iterative feedback mechanism ensures that the dataset evolves toward higher quality, mimicking the careful curation a human data scientist would perform—but at scale and with minimal human intervention.
The framework also offers internal flexibility: researchers can adjust the analysis criteria, define custom tools, or integrate external knowledge sources. This makes Autodata a versatile platform for domains from medicine to law, where high-quality training data is scarce and expensive.
Conclusion
Autodata represents a paradigm shift from static synthetic data generation to an autonomous, iterative process. By giving AI agents the role of data scientists, Meta’s RAM team has addressed one of AI’s most stubborn bottlenecks. The result is a framework that doesn’t just generate data—it crafts bespoke, high-quality datasets that push model performance further. As synthetic data continues to play a critical role in AI development, Autodata may well become the standard for building robust, reliable training sets.
For more details, visit the official Autodata blog post.
Related Articles
- Orion's Flywheel: A Deep Space Fitness Solution with Ryan Schulte
- Android XR: The Turning Point for Google's Wearable Vision
- Global Forest Loss Declines, but Challenges Persist as Deforestation Regulations Evolve
- The Explosive Power of Evaporating Droplets: New Frontiers in 3D Printing and Chemical Analysis
- How to Train AI Agents to Minimize Redundant Tool Calls with HDPO Framework
- Unboxing the Ultimate Lego Star Wars Yoda Bust: Questions and Answers
- Hubble Captures Dazzling New View of Spiral Galaxy NGC 3137, Offering Clues to Our Milky Way's Past
- How to Trace the Origins of the Coruna Exploit Kit: Linking It to Operation Triangulation